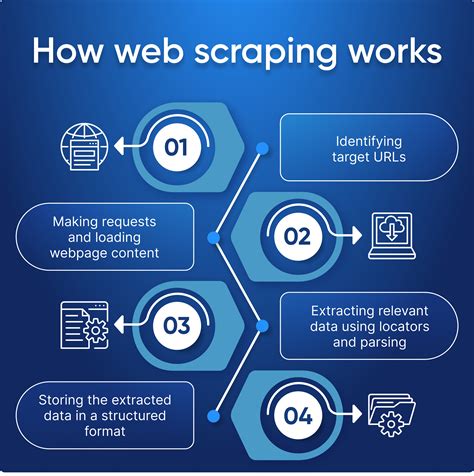
在這數位化時代,數據就是金礦!任何企業或個人若能有效掌握數據,便能在市場中占有一席之地。網頁爬蟲,這項技術正是協助我們發掘這座數據金礦的利器。今天,我們將深入探討如何運用網頁爬蟲技術來進行實時數據處理,並如何在這個過程中,使用各種工具來提高效率和準確性。
初探網頁爬蟲的世界
網頁爬蟲,顧名思義,就是能夠在網路上自動蒐集資料的小程式。這些程式能夠自動瀏覽網站,並將所需的資料下載到本地端。這項技術不僅適用於靜態頁面,甚至能夠應用於動態網頁。隨著技術的發展,網頁爬蟲已成為資料科學家和開發者手中不可或缺的工具。
Requests庫是什麼?
Python中的Requests庫是一個非常強大的HTTP請求工具。它可以讓使用者輕鬆地發起HTTP請求,並獲取網頁的HTML內容。這裡有個小秘訣:使用Requests庫發起請求時,記得檢查返回的狀態碼,這能告訴你請求是否成功。例如,狀態碼200通常表示請求成功,而404則表示頁面不存在。
import requests
response = requests.get('https://www.example.com')
if response.status_code == 200:
print('成功取得資料!')
else:
print('取得資料失敗,請檢查網址。')
從HTML中提取資料的魔法
獲取網頁內容後,接下來的步驟是從HTML中提取有用的資料。這裡要介紹的是兩個常用的Python庫:BeautifulSoup和Scrapy。
BeautifulSoup: 解剖HTML的利器
BeautifulSoup是一個簡單易用的工具,可以用來解析HTML和XML文件。它提供了一個Pythonic的方式來導航、搜索和修改樹形結構中的資料。
from bs4 import BeautifulSoup
html_doc = """<html><head><title>網頁標題</title></head>
<body><p class="title"><b>這是一個段落</b></p></body></html>"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.title.string)
Scrapy: 強大的網頁爬蟲框架
Scrapy是一個功能強大的爬蟲框架,適合用於需要處理大量網頁的情況。它能夠高效地解析網頁,並提供強大的擷取和存儲功能。
進階:動態網頁數據抓取
隨著網頁技術的進步,越來越多的網站使用JavaScript來動態生成內容。這使得傳統的爬蟲技術面臨挑戰。但別擔心,我們有Appium和mitmdump這兩個好幫手。
Appium和mitmdump的完美搭配
這兩個工具能夠協助我們抓取動態網頁的資料。Appium專注於移動應用的自動化測試,而mitmdump則是一個中介代理,可以截取HTTP請求和回應。兩者配合使用,能夠有效地擷取京東等網站的數據。
爬蟲API:簡單高效的數據獲取方式
隨著雲計算和Web服務的普及,許多公司推出了爬蟲API。這些API讓使用者可以通過調用API端點來獲取特定的資料,而無需親自編寫爬蟲程式。這不僅簡化了數據獲取的過程,也提高了效率。
爬蟲API的優勢
- 簡單易用: 無需深入了解爬蟲技術,便能輕鬆獲取資料。
- 高效穩定: 通過API獲取資料的速度和穩定性通常高於自行編寫的爬蟲。
- 減少法律風險: 使用官方API通常符合網站的使用條款,減少了法律風險。
實戰練習:以京東商品為例
假設我們的目標是抓取京東商城上的商品資料,從價格到用戶評價都需要詳細掌握。以下是簡單的步驟:
- 定位目標網址: 確定要抓取的商品頁面網址。
- 使用Requests庫取得HTML: 發起HTTP請求,獲取網頁內容。
- 解析HTML並提取資料: 使用BeautifulSoup或Scrapy解析HTML,提取商品標題、價格等資訊。
- 將資料存儲到本地或數據庫: 結合使用Pandas等庫來存儲和分析資料。
# 簡單的爬蟲例子
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://www.jd.com/product/123456.html'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('div', class_='title').text
price = soup.find('span', class_='price').text
data = {'商品名稱': [title], '價格': [price]}
df = pd.DataFrame(data)
df.to_csv('products.csv', index=False)
常見問題解答
如何處理被封鎖的問題?
使用代理伺服器或設置請求頭來模擬正常用戶的行為,可以有效減少被封鎖的機率。
BeautifulSoup和Scrapy應該選擇哪一個?
如果是小型項目或需要快速上手,選擇BeautifulSoup。如果是大型項目,且需要高效抓取大量資料,Scrapy是更好的選擇。
如何處理動態網頁中的JavaScript生成內容?
可以使用Selenium或Appium等工具來模擬瀏覽器行為,抓取動態生成的內容。
是否所有網站都可以使用爬蟲抓取資料?
不是所有網站都允許爬蟲抓取資料。使用者應閱讀網站的robots.txt文件和服務條款,確保不違反規定。
爬蟲API和自行開發爬蟲哪個更好?
如果網站提供了官方API,使用API會更簡單且合法。但若沒有API或需要自定義資料,則可能需要自行開發爬蟲。
如何保存爬取到的數據?
可以將數據存儲到本地文件(如CSV、JSON)或使用數據庫(如MySQL、MongoDB)進行管理和分析。
結論
網頁爬蟲技術在現代數據科學中扮演著不可或缺的角色。無論是使用Requests庫發起HTTP請求,還是運用BeautifulSoup和Scrapy解析HTML,這些工具都能讓我們更有效地從網絡中提取有用的數據。隨著技術的不斷進步,未來的網頁爬蟲將會變得更加智能和高效。希望今天的分享能讓你對網頁爬蟲有更深入的了解,並能在實際操作中獲得成功!