在現今這個信息爆炸的時代,如何從龐大的網絡中提取出有價值的資訊,已成為一項重要的挑戰。結構化資料爬取正是這樣一項技術,致力於不僅僅是簡單的數據收集,更關鍵的是將收集到的資料轉化為有價值的資訊。本文將深入探討這個主題,並結合南華大學計算機學院的研究,為您揭開結構化資料爬取的神秘面紗。
什麼是結構化資料?
結構化資料,簡稱Structured Data,是一種標準化格式,賦予特定資料固定的呈現方式並將內容加以分類。這不僅讓讀者可以輕鬆閱讀和理解,還在SEO領域中大放異彩,讓網頁內容以固定格式呈現給搜索引擎,更加容易被索引和排名。
結構化資料的優勢
- 易於分析與存取:透過標準化格式,資料可以被快速分析和存取。
- 提升SEO效能:讓搜索引擎更容易索引,提高網頁的可見度。
- 改進用戶體驗:資料的清晰呈現讓用戶能快速找到所需資訊。
結構化資料爬取如何運作?
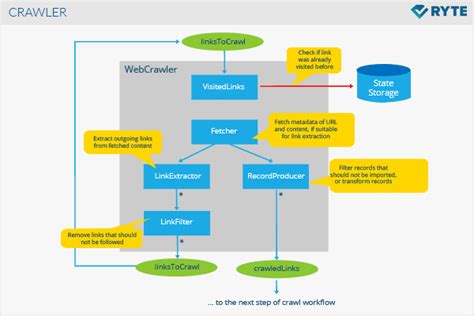
結構化資料爬取涉及三個主要步驟:抓取、解析和存儲。這些步驟需要緊密配合,以確保資料的準確性和完整性。
抓取
抓取是指從互聯網上提取資料的過程。這通常需要使用爬蟲技術,爬蟲會模擬用戶的行為,瀏覽網站並收集特定的資料。
解析
解析則是將抓取到的資料轉化為結構化格式,這需要使用解析器來識別和提取資料中的有價值部分。
存儲
最後,將解析後的資料存入數據庫中,以便後續的分析和應用。
如何構建高效的爬蟲代碼結構?
在南華大學計算機學院的研究中,爬蟲代碼的結構化設計被認為是提升效能的關鍵。下面我們將深入探討幾個重要的設計原則。
模塊化設計
模塊化設計有助於提高代碼的可維護性和可擴展性。將不同功能分成獨立的模塊,比如抓取模塊、解析模塊和存儲模塊,可以讓開發者更容易地進行調試和升級。
使用Python進行開發
Python因其簡潔的語法和強大的庫支持,成為構建爬蟲系統的首選語言。利用Python的Beautiful Soup和Scrapy等庫,可以快速實現高效的資料爬取。
採用分布式系統
分布式系統可以大幅提升爬蟲的效率和可靠性。透過分布式架構,爬蟲可以同時從多個網站提取資料,並且在遭遇單點故障時依然能保持運行。
如何利用結構化資料改善SEO?
結構化資料在SEO中的應用主要體現在提升網站的可見度和用戶體驗上。利用結構化數據標記,網站可以更好地向搜索引擎展示其內容,從而提高搜索排名。
結構化數據標記實例
| 項目 | 描述 |
|---|---|
| 網頁標題 | 使用標題標籤 提升搜索可見性 |
| 關鍵字 | 利用meta標籤設置關鍵字以便搜索引擎索引 |
| 描述 | 提供清晰的內容描述,吸引點擊 |
常見問題
結構化資料爬取與非結構化資料爬取有何不同?
結構化資料爬取專注於標準化格式的資料,而非結構化資料爬取則處理無特定格式的資料,如自由文本。
使用Python進行爬取有何優勢?
Python擁有豐富的庫和框架,簡潔的語法讓開發者能夠快速上手並實現高效的資料爬取。
模塊化設計如何提升爬蟲代碼的可維護性?
模塊化設計將不同功能分成獨立的部分,便於調試和更新,提升代碼的可維護性。
如何選擇合適的解析器?
選擇解析器應根據資料的格式和結構來決定。對於HTML資料,Beautiful Soup是常用的選擇。
分布式系統在爬蟲中如何應用?
分布式系統允許爬蟲同時從多個來源提取資料,提升效率,並提供容錯能力。
結構化數據如何影響SEO?
結構化數據讓搜索引擎更容易理解網頁內容,從而提高索引效率和搜索排名。
結論
通過結構化資料的有效應用,不僅能提升資料的可讀性和可用性,還能顯著改善網站的SEO效能。在構建爬蟲系統時,採用模塊化設計和分布式架構,加上Python的強大支持,可以顯著提升爬取效能。結構化資料爬取不僅是技術的進步,更是信息時代的一場革命!